


Here you will understand AWS S3 Bucket usage through AWS CLI. Get to know how to access and store data in a S3 bucket using the AWS CLI:
Amazon S3 which is also known as Simple Storage Service. It provides scalable and secure object storage through a web interface. So, teams can store and protect any amount of data.
The use cases where it can be used are for backups, websites, archiving, storing log files, videos, pictures, etc.
Table of Contents:
What is AWS S3 Bucket

The S3 service stores the data as objects within BUCKETS. The S3 bucket is a public cloud storage resource and is also a container for the objects.
To store your data in Amazon S3, first create a bucket and then specify a bucket name and AWS Region. Upload your data to that bucket as objects in Amazon S3 either through the web interface or using AWS CLI.
With Amazon S3 you can upload a file with a maximum size of 5GB else you will need to break it into parts.
In this document, we will look at how to access and store data in S3 bucket using the AWS CLI. The AWS CLI provides automation options through the CI/CD pipelines and hence it becomes a powerful utility to use through the command line.
Features of S3:
Amazon S3 provides a highly scalable, durable, and protected infrastructure for the storage of objects. It offers the following features:
- Data encryption during the transmission i.e., protection of data.
- Versioning of objects.
- Replication of data to different AWS regions.
- Bucket policy to allow or disallow access to S3 objects.
- Fast and secured transfer of files over long distances using edge locations closest to the team’s location and S3 bucket.
Use Cases of S3:
S3 can be used to store and protect data for a wide range of use cases. Static website hosting, storing static content like images and video files, log files storing for monitoring and troubleshooting, data archival, enterprise applications, mobile apps, data backup, long-term archiving, configuration files and of course, software delivery is a few scenarios where S3 could be used.
AWS S3 Pricing
The AWS S3 on Free Tier offers 5GB of free storage. Visit here for other pricing plans for more storage options.
The below picture shows a snapshot of usage of the S3 bucket from an end-user perspective with an appropriate role:

Installing AWS CLI
Get the latest version of the AWS CLI for your operating system from the latest version of the AWS CLI – AWS Command Line Interface (Amazon.com)
Creating and Uploading Files to AWS S3 Bucket
In this section, we will see the usage of the AWS CLI with the S3 bucket. To interact with the S3 bucket, we will first need to create a user with AmazonS3FullAccess permission in the Identity and Access Management (IAM) service.
Open IAM and create a new user. For e.g, s3admin
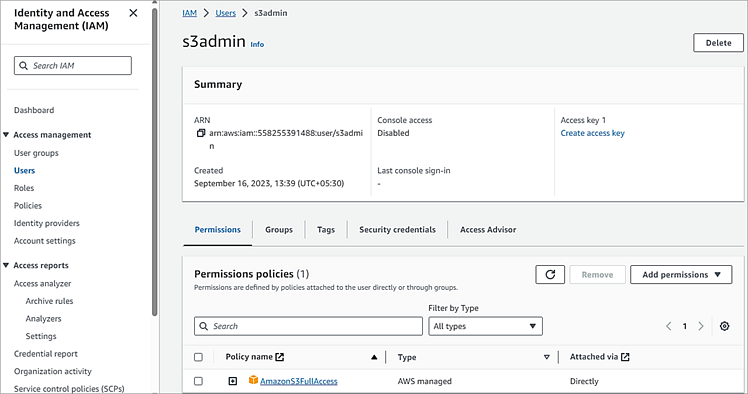
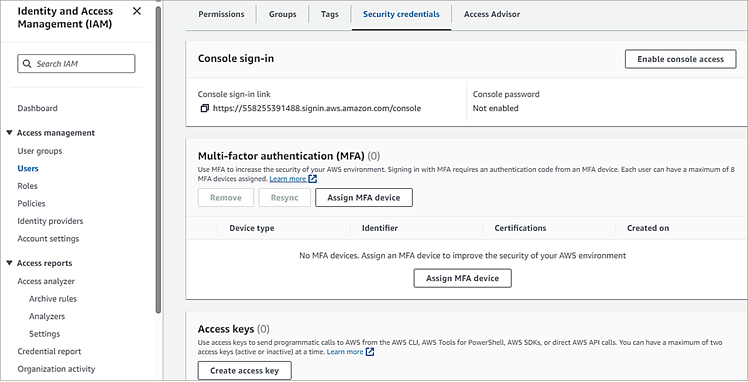
Go to the Security credentials tab. Click on Create Access Key under Access keys. Save the Access Key ID and Secret Key.
On the machine where AWS CLI is installed, run the command: aws configure
The above command helps in configuring the AWS CLI. It will then ask you to enter the Access Key ID, Secret Key, Default region, and Default output format as JSON.
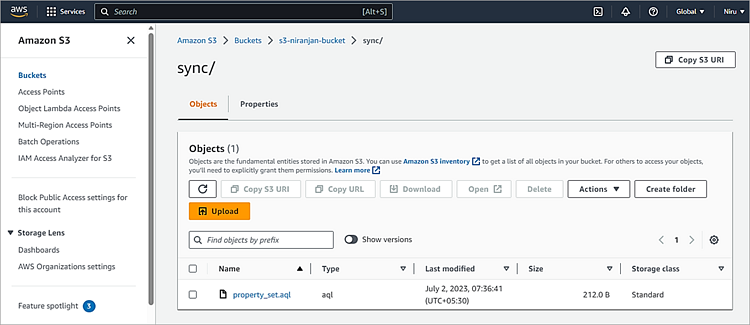
In the S3 service, create an S3 bucket and a folder called ‘sync’ using the web interface. Click on Copy S3 URI which will need to be provided in the CLI command.
Let’s now look at various examples on uploading files to the S3 bucket
Example #1: Create S3 bucket using CLI
was s3 mb s3://niranjan-cli-s3-bucket

However, the bucket name used in the document is s3-niranjan-bucket. Bucket names have to be globally unique.
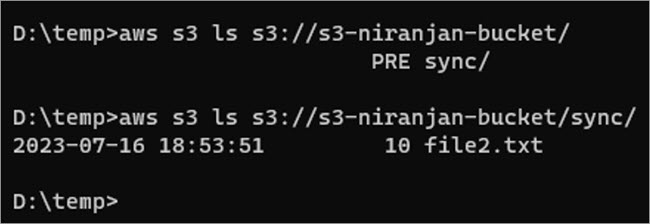
Example #2: List buckets and the objects in the bucket
Use the below command to list the buckets and the objects inside it.
aws s3 ls s3://s3-niranjan-bucket/
aws s3 ls s3://s3-niranjan-bucket/sync/
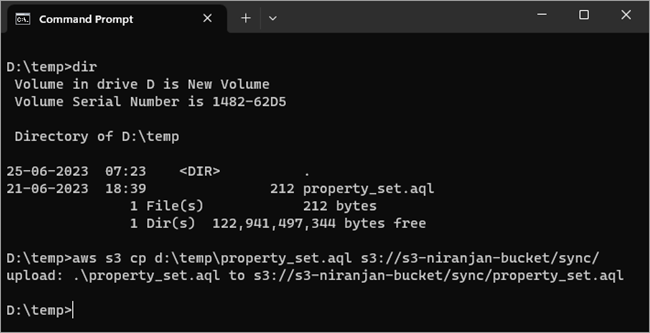
Example #3: Copy Individual file
aws s3 cp d:\temp\property_set.aql s3://s3-niranjan-bucket/sync/
Example #4: Uploading ALL Multiple Files and Folders to S3 Recursively
In this example, we will look at how to upload the files and the folders recursively.

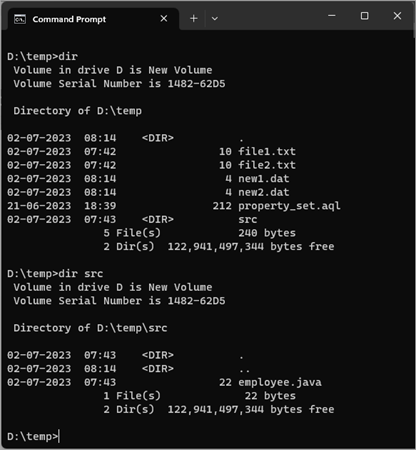
aws s3 cp d:\temp\ s3://s3-niranjan-bucket/sync/ –recursive


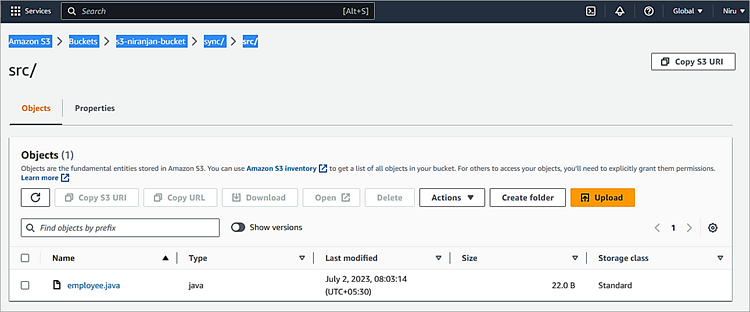
Example #5: Uploading Multiple Files and Folders to S3 bucket selectively
Example, Copy only .java file(s)
aws s3 cp d:\temp\ s3://s3-niranjan-bucket/sync/ –recursive –exclude * –include *.java

E.g., Copy only file1.txt
aws s3 cp d:\temp\ s3://s3-niranjan-bucket/sync/ –recursive –exclude * –include f*1.txt


E.g., Copy only .txt and .java files:
aws s3 cp d:\temp\ s3://s3-niranjan-bucket/sync/ –recursive –exclude * –include *.txt –include *.java
Here exclude .dat files from the upload.

Downloading Files From S3 Bucket
In this section, we will look at downloading the files and folders from the S3 bucket.

aws s3 cp s3://s3-niranjan-bucket/sync/ d:\temp –recursive
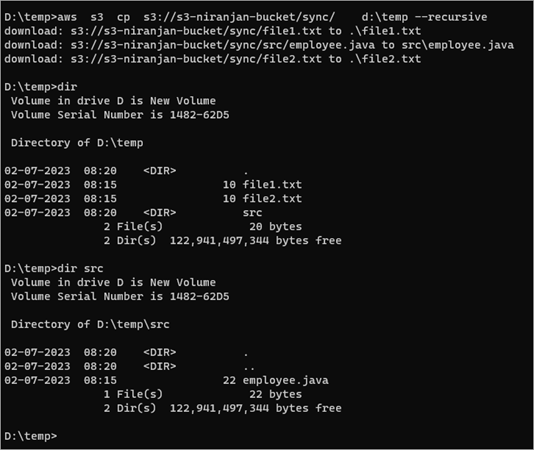
Copy Files Between S3 Buckets
In this section, we will look at how to copy files between two S3 buckets.
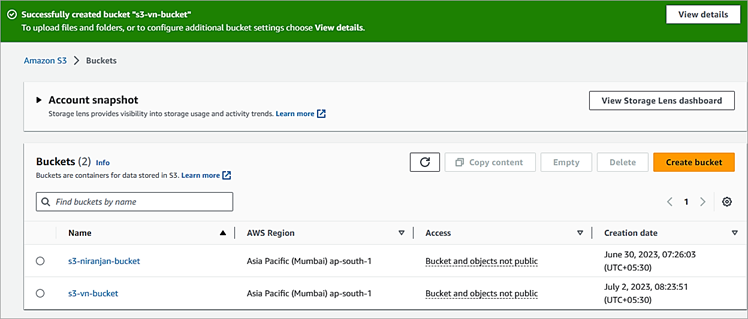
aws s3 cp s3://s3-niranjan-bucket/sync/file1.txt s3://s3-vn-bucket/

Synchronizing Files and Folders With S3
In this section, we will look at another file operation command available in AWS CLI for S3, which is the sync command.
Sometimes you need to keep the contents of an S3 bucket updated and synchronized with a local directory on a server. For example, we may need to keep transaction logs on a server synchronized to S3 at regular intervals.
Let’s look at how to sync files using the aws s3 sync command.
E.g., modify file1.txt
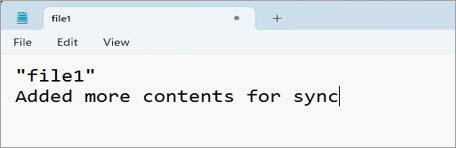
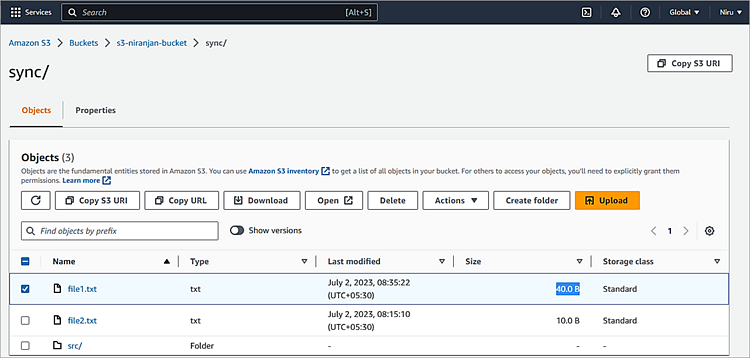
File size of file1.txt is 40 bytes after modification. The sync command will pick up that modification to the file and upload the changes done on the local file to the S3 bucket, as shown below.

aws s3 sync d:\temp\ s3://s3-niranjan-bucket/sync/ –exclude * –include *.txt
The file size in the S3 bucket is also 40 bytes.
Synchronizing Deletions with S3
By default, the sync command does not process any deleted objects. Any file deleted from the source location, which is a local folder, is not removed at the destination in the s3 bucket unless you use the –delete option.
In this next example, the file named file1.txt has been deleted from the source. We will append the command to synchronize the files command to synchronize the files will be appended with the –delete option, as shown in the code below.
aws s3 sync d:\temp\ s3://s3-niranjan-bucket/sync/ –exclude * –include *.txt –delete

Deleting S3 Bucket and Objects
To delete an object in the bucket, use the following command.
aws s3 rm s3://[bucket-name]/[folder-name]/[file-name]
Example,
aws s3 rm s3://s3-niranjan-bucket/sync/file2.txt

To delete all objects inside the folder, use the following command with the –recursive option
aws s3 rm s3://[bucket-name]/[folder-name] –recursive
To delete an S3 bucket along with all objects, use the following command:
aws s3 rb s3://[bucket-name] –-force
Example: aws s3 rb s3://s3-niranjan-bucket –force

If –force option is not used then we will need to empty the bucket and then delete the S3 bucket.
How to Make AWS S3 Bucket Public
To make a S3 bucket public, go to the Permission TAB by clicking on the S3 bucket and uncheck Block all public access. Click on Save Changes.

Frequently Asked Questions
EC2 instance is like a remote machine running Linux or Windows on which a user can install any software whereas kinds S3 is a storage service to store various kinds of files.
Amazon S3 is an easy-to-use, scalable, flexible, and cheap storage service. You can use S3 to store any amount of data and it supports various formats of data. The data is most unlikely to be lost in case of any hardware failures.
S3 is better for storage because it keeps multiple versions of the object in the same bucket and can retrieve/restore any version of the object as part of rollback due to application failures.
Conclusion
In this article, we have seen how easy it is to manage the S3 buckets and objects from the CLI. We observed the example commands for uploading, downloading, syncing, and deleting objects.
The AWS CLI gives us very good automation options through our CI/CD pipeline, especially when you need to upload any binary artifacts or log files to the S3 bucket.
Suggested Read = >> Best Amazon AWS DevOps Tools
Was this helpful?
Recommended Reading
-

Tutorial on Automated Deployment Using AWS CodeDeploy: In Part 2 of the AWS DevOps tools, we saw how the CodeBuild service was used to build the J2EE project using Maven. In this tutorial, we will see how the artifact WAR file that is stored in the S3 bucket can be…
-

AWS CodeBuild DevOps Tool: In Part 1 of the AWS DevOps tools, we saw how CodeCommit service was used to store the source code in a secure online version control service which is a pre-requisite for any DevOps implementation. In Part 2 of the series, we will learn more about…
-

DevOps Using AWS (Amazon Web Services) CodeCommit Repository: In our previous tutorial on DevOps with Microsoft VSTS, we came to know more about VSTS. In this new 3 part series, I will focus on a hands-on approach for DevOps (CI and CD) using Amazon Web Services (AWS) cloud DevOps service tools.…
-

Learn .NET Web application deployment using AWS Elastic Beanstalk: We gained knowledge on AWS CodeDeploy in our previous tutorial. AWS Elastic Beanstalk is primarily a deployment service which helps to deploy your application quickly to different environments on the cloud. Read Through => Simple DevOps Training Series AWS Elastic…
-
AWS is a world leader in the industry of cloud computing. But for new users, it's difficult to configure AWS servers. This is where Managed Cloud Hosting Services can be helpful. This is a detailed review of how you can use Cloudways Managed AWS Cloud Hosting Service and take advantage…
-
Top AWS Managed Service Provider Companies and Vendors: AWS stands for Amazon Web Services. Amazon web services provide a cloud-based platform for many services like database storage etc. AWS is used by several business organizations as it helps the business to grow by giving flexible and cost-effective solutions. Let's explore…
-
In this tutorial, we have provided the most frequently asked AWS (Amazon Web Services) interview questions & answers with explanations: In constantly uncertain economic situations prevailing globally, many organizations are considering moving to public cloud computing and storage services offered by Amazon. In startup software industries, the DevOps team needs…
-
Best Amazon AWS DevOps Tools: A pipeline, source code repository, build, and deployment with Amazon Web Services When I started my software career around 20+ years back the infrastructure (Software and Hardware) for any kind of development and deployment had to be procured. This included placing orders with the vendor…







